Stop Re-downloading Your Models: A Practical Guide to Model Caching on Kubernetes with GKE
Download a large LLM once, mount it everywhere. A practical guide to caching Hugging Face models on Kubernetes with a PVC, a download Job, and vLLM on GKE.
Key Takeaways
- Without a cache, every pod restart re-downloads the full model from Hugging Face, and a 65 GB pull can leave expensive GPUs idle for 20 to 40 minutes.
- The pattern needs exactly two Kubernetes objects: a ReadWriteMany PersistentVolumeClaim for the weights and a one-time download Job that fills it.
- ReadWriteMany (RWX) storage, like GKE Filestore, lets one cached copy serve every replica on every node; RWO block storage breaks the moment a second node needs the volume.
- Pin the model to a commit SHA instead of main so the cache behaves like a lockfile, and set the same HF_HOME in the download Job and every inference pod.
- Run downloads on cheap CPU nodes with HF_XET_HIGH_PERFORMANCE=1 and generous memory; GPUs should load weights and serve tokens, not wait on progress bars.
Large language models are big. Qwen3-32B is roughly 65 GB of safetensors. Llama 3 70B is over 140 GB. DeepSeek variants push past 600 GB. Every time a pod starts without a cache, it pulls that entire payload from Hugging Face over the internet, and your expensive GPU sits idle while it waits.
Now multiply that by reality. Inference workers restart. Deployments scale from 2 replicas to 8. You tear down a benchmark and redeploy it with different flags. Without a cache, every one of those events is a full re-download. A 65 GB pull at 500 MB/s is still around 20 minutes, and most clusters do not sustain 500 MB/s from the Hub across parallel pods.
Put a price on that. A 2x A100 80GB node on GCP runs about $12.50 an hour, so a 30-minute cold download is roughly $6.25 of idle GPU time. Per pod. Per restart. Restart ten times in a week of benchmarking and iterating, and you have spent over $60 downloading the exact same bytes while two A100s did nothing. The meter runs whether your GPUs are generating tokens or waiting on a progress bar.
A model cache fixes this with one idea: download the model once to shared storage, then let every pod mount it. This post covers why it matters, when to do it, the parameters that actually matter, and a complete working example you can apply today.
This post walks through a practical example of caching a medium-sized model, Qwen/Qwen3-32B, on Kubernetes. You'll learn how to download the model once, store it on shared storage, and reuse it across multiple inference pods, eliminating repeated downloads and reducing GPU startup time.
The Problem in One Picture
Without a cache, the download is inside your scaling path:
Pod starts -> pulls 65 GB from the Hub -> loads weights -> ready (20-40 min)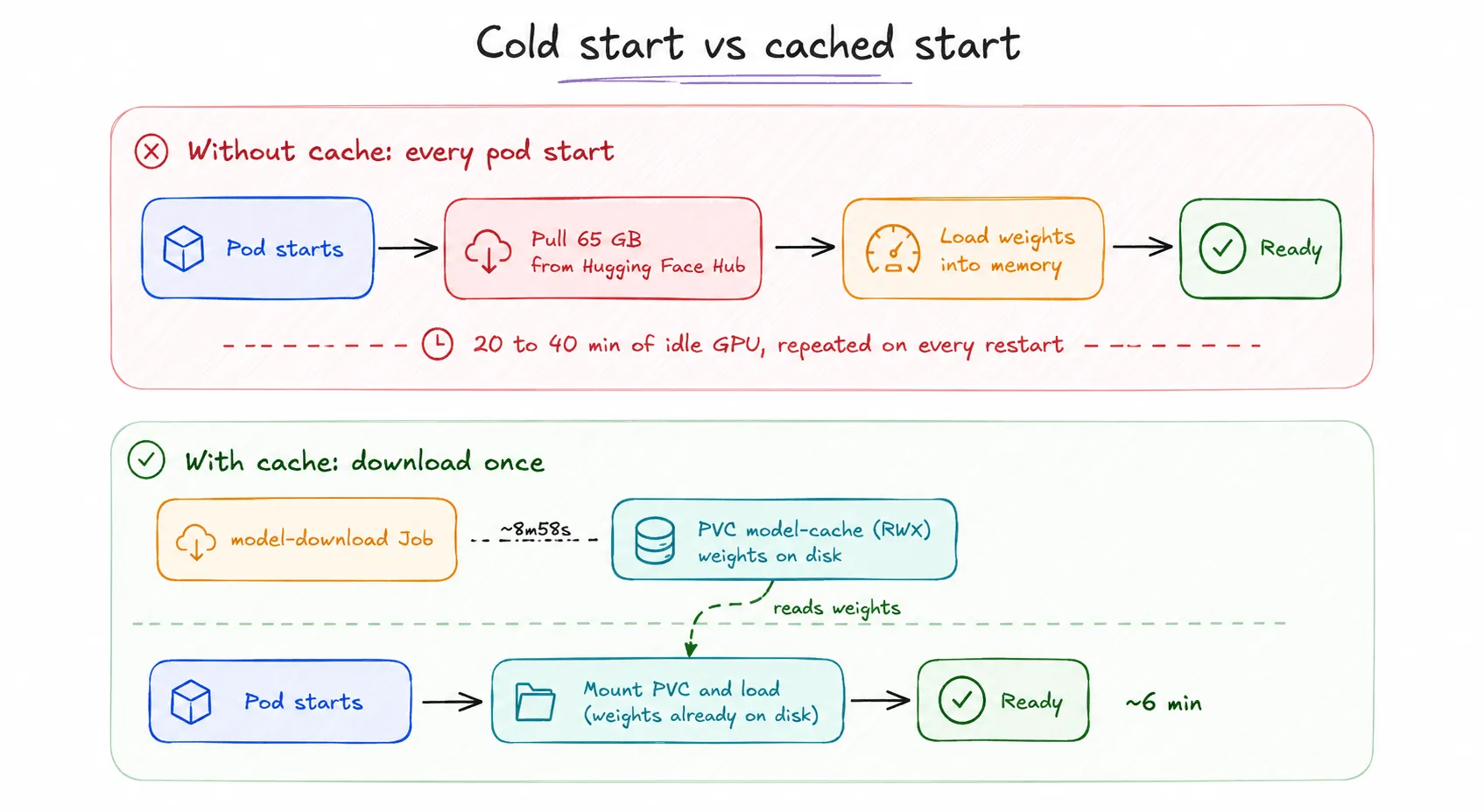
With a cache, it is not:
Job downloads once -> PVC holds the weights
Pod starts -> mounts PVC -> loads weights -> ready (1-3 min)The download still happens. It just happens once, ahead of time, in a cheap CPU pod instead of blocking a GPU pod.
When You Should Cache
Cache the model when any of these are true:
- The model is large. Anything above ~10 GB is worth caching. Above 50 GB it is not optional.
- You run more than one replica. Ten workers pulling the same 65 GB independently is 650 GB of redundant egress and ten cold starts.
- Pods restart or autoscale. Spot instances, node drains, HPA scale-ups. Every restart without a cache is a full re-pull.
- You benchmark or iterate. Deploy, measure, tweak, redeploy. The model does not change between runs, so stop downloading it between runs.
- Your GPU time is expensive. At $12.50 an hour for a 2x A100 node, every cold download is money spent on idle silicon.
Skip the cache when the model is small (a few GB), you run a single short-lived experiment, or your platform already bakes weights into the container image or node image. For everything else, cache first, deploy second.
The Pattern: A PVC and a Download Job
The pattern has exactly two Kubernetes objects:
- A PersistentVolumeClaim that holds the weights on shared storage.
- A Job that downloads the model into that PVC once.
Your inference workloads then mount the same PVC read-only and find the weights already on disk. This is the exact pattern NVIDIA Dynamo ships in its recipes, and it works for any serving stack: vLLM, SGLang, TensorRT-LLM, or plain PyTorch.
Step 0: Environment
For this walkthrough, we'll cache Qwen/Qwen3-32B on Google Kubernetes Engine before serving it with vLLM. The cluster is intentionally sized to separate model preparation from inference.
| Component | Configuration | Purpose |
|---|---|---|
| CPU nodes | 2 × n2-standard-32 (32 vCPUs, 128 GB RAM each) from GCP | Dedicated to Kubernetes system workloads, shared storage, and the model download Job. The download Job enables HF_XET_HIGH_PERFORMANCE=1, which significantly increases download throughput by using aggressive parallel transfers, but can require up to 64 GB of RAM. The 128 GB memory available on n2-standard-32 instances provides ample headroom for these transfers while keeping expensive GPU nodes focused entirely on inference. |
| GPU nodes | 2 nodes, each with 2 × NVIDIA A100 80 GB GPUs (4 GPUs total) from GCP | Dedicated to serving inference. The large GPU memory comfortably accommodates the model weights while leaving substantial room for the KV cache, enabling long-context inference and higher request concurrency. |
| Shared storage | Google Filestore (ReadWriteMany) | Stores the Hugging Face cache so the model is downloaded exactly once and shared across every inference pod. |
| Model | Qwen/Qwen3-32B | Approximately 61-65 GB of safetensors, making it an excellent example of why model caching dramatically reduces startup time and eliminates repeated downloads. |
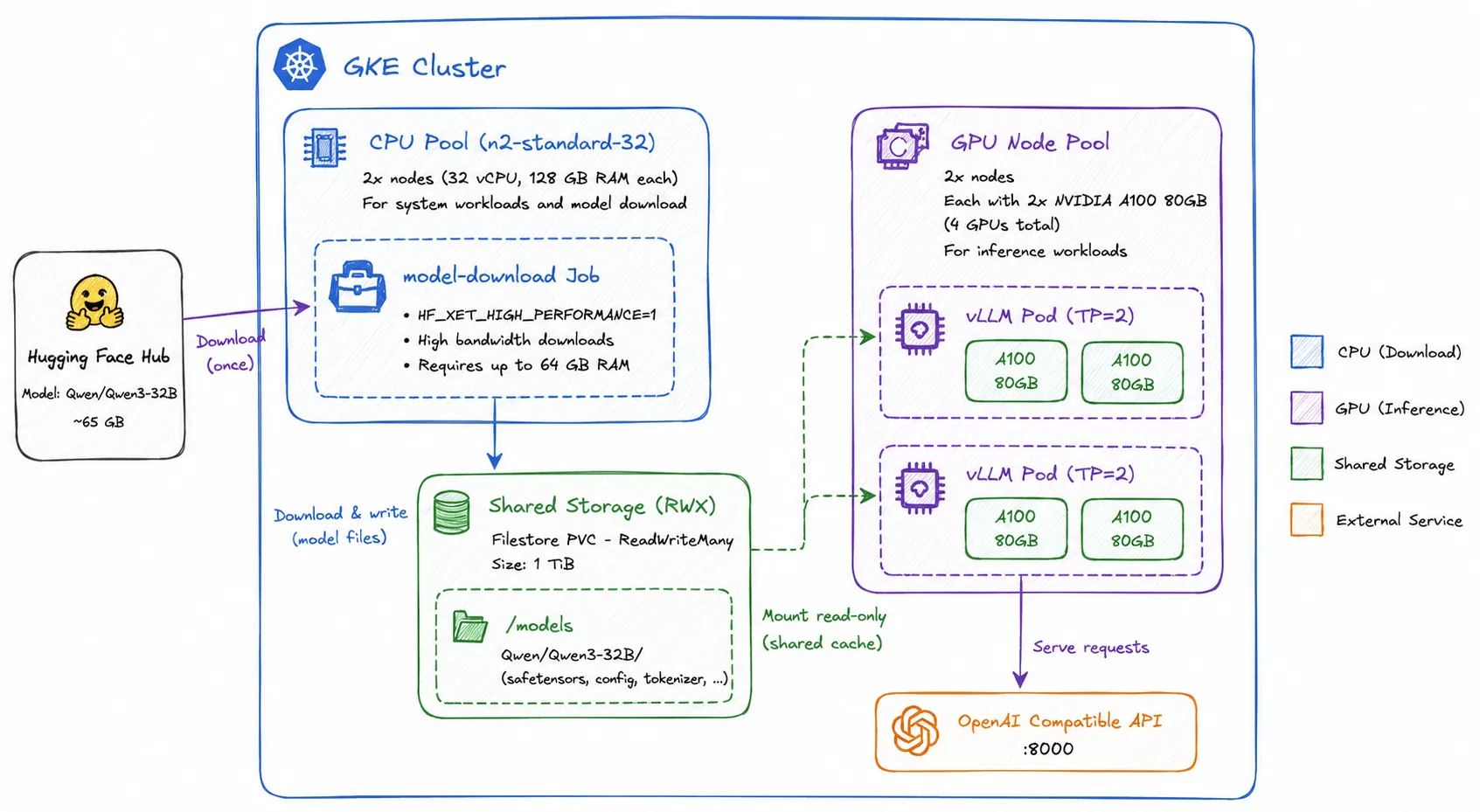
This architecture keeps CPU-intensive tasks, such as downloading and caching models, completely separate from GPU inference. The model download Job runs only on the CPU nodes, leveraging HF_XET_HIGH_PERFORMANCE=1 and their abundant memory to maximize download bandwidth.
Once the weights are cached on the shared RWX volume, every vLLM pod mounts the cache directly and loads the model from local storage instead of downloading it again. As a result, the A100 GPUs spend their time loading weights into GPU memory and serving requests, rather than sitting idle while waiting for model downloads to finish.
Step 1: The Storage
We are running this experiment on GKE, so before writing the PVC, look at what the cluster actually offers:
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
dynamic-rwo pd.csi.storage.gke.io Delete WaitForFirstConsumer true 68s
premium-rwo pd.csi.storage.gke.io Delete WaitForFirstConsumer true 69s
standard kubernetes.io/gce-pd Delete Immediate true 68s
standard-rwo (default) pd.csi.storage.gke.io Delete WaitForFirstConsumer true 68sEvery class here is backed by Persistent Disk, and the -rwo suffix tells you the story: block storage, ReadWriteOnce, mountable by one node at a time. We want ReadWriteMany, so the cache outlives any single node and every future replica can mount it simultaneously. On GKE that comes from the Filestore CSI driver, which is one command to enable:
gcloud container clusters update your-cluster \
--update-addons=GcpFilestoreCsiDriver=ENABLED \
--region your-regionOnce it is on, kubectl get sc grows a set of -rwx classes (standard-rwx, premium-rwx), and the PVC becomes:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: model-cache
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Ti
storageClassName: standard-rwxThree parameters carry all the weight here.
accessModes: ReadWriteMany. This is the one people get wrong, so be deliberate about it. RWX means the volume is a shared filesystem that any number of pods on any number of nodes can mount at once: the download Job writes it, and every inference replica reads it in parallel. This is what lets the pattern scale from our single GPU node today to a fleet tomorrow without touching anything but the replica count. On other platforms the equivalents are EFS on EKS, Azure Files, CephFS, or NFS. A block-backed RWO class also works if you are certain you will only ever run one node, but the moment a second pod lands on a different node it hangs in Pending forever, so RWX is the safer default.
storage: 1Ti. More than the 1.5x-model-size rule suggests, and that is Filestore talking: the basic tier provisions a minimum 1 TiB instance, so a 100Gi request gets rounded up and billed as 1 TiB anyway. Ask for what you will be billed for.
storageClassName: standard-rwx. There is no universal choice, only what kubectl get sc shows you. standard-rwx is HDD-backed Filestore, and its read throughput sets your pod cold-start floor since every worker streams weights from it at load time. If loading 65 GB needs to be faster, premium-rwx is SSD-backed at a higher minimum size and price. However, it has a 2 TiB minimum storage, so it might be overkill.
Step 2: The Download Job
apiVersion: batch/v1
kind: Job
metadata:
name: model-download
spec:
backoffLimit: 3
template:
spec:
restartPolicy: Never
containers:
- name: model-download
image: python:3.10-slim
command: ["sh", "-c"]
envFrom:
- secretRef:
name: hf-token-secret
env:
- name: MODEL_NAME
value: "Qwen/Qwen3-32B"
- name: MODEL_REVISION
value: 9216db5781bf21249d130ec9da846c4624c16137
- name: HF_HOME
value: /cache/huggingface
- name: HF_XET_HIGH_PERFORMANCE
value: "1"
args:
- |
set -eux
pip install --no-cache-dir huggingface_hub==1.22.0
hf download $MODEL_NAME --revision $MODEL_REVISION
resources:
requests:
cpu: "2"
memory: "64Gi"
limits:
cpu: "8"
memory: "64Gi"
volumeMounts:
- name: model-cache
mountPath: /cache/huggingface
volumes:
- name: model-cache
persistentVolumeClaim:
claimName: model-cacheEvery parameter here earns its place. Walk through them.
backoffLimit: 3. Downloads fail. The Hub rate limits, networks blip, a 65 GB transfer has a lot of surface area. This retries the Job up to three times before giving up, and the Hugging Face client resumes partial downloads, so retries do not start from zero.
restartPolicy: Never. Jobs need it, and it keeps failed attempts visible as separate pods so you can read their logs instead of losing them to a restart loop.
hf-token-secret. Gated models (Llama, and most frontier open-weights releases) require an authenticated token. Create it once:
kubectl create secret generic hf-token-secret \
--from-literal=HF_TOKEN="your-token"The envFrom injects it as HF_TOKEN, which the CLI picks up automatically. Never bake tokens into images or manifests. One rule to remember: the secret must live in the same namespace as the download Job, so if you deploy into a dedicated namespace instead of the default one, add -n your-namespace to this command and every command that follows.
MODEL_REVISION. Pinning to a commit SHA instead of main makes the cache reproducible. Model repos get updated: tokenizer fixes, config changes, sometimes reuploaded weights. If you resolve main today and again next month, you can silently end up serving a different model than the one you benchmarked. Pin the SHA, and your cache is a lockfile, not a moving target like a floating Docker tag.
HF_HOME. Points the entire Hugging Face cache layout at the mounted volume. Your inference pods must set the same value (or mount the volume at the same path) so the client finds the blobs instead of re-downloading. If the paths do not match, the cache exists but nobody uses it.
HF_XET_HIGH_PERFORMANCE. Enables aggressive parallel chunked transfers via Xet storage. The tradeoff is memory: high-performance mode can use up to 64 GB of RAM for download buffers, which is exactly why this Job requests 64Gi on a 128 GB node (some RAM is reserved for other system-critical pods). On smaller nodes, set it to "0" and drop the memory request to something like 8Gi. The download is slower, but it fits. Here we want a full performance demo, though! (Not necessary, but for this experiment we're considering the best possible performance.)
resources. Requesting explicit CPU and memory does two things: it guarantees the buffers described above actually fit, and it stops a hungry download from starving neighbors on the node. Note what is absent: no GPU. Downloading weights is a network and disk task, so ideally, we shouldn't burn an accelerator on it.
Step 3: Run It and Wait
# create the storage
kubectl apply -f cache.yaml
# start the download
kubectl apply -f model-download.yamlYou can watch progress in the meantime:
kubectl logs -f job/model-downloadWhen the pull is done, the Job says so:
$ kubectl get jobs
NAME STATUS COMPLETIONS DURATION AGE
model-download Complete 1/1 8m58s 9m58sThat is 61 GB of Qwen3-32B on the shared volume in under nine minutes, pip install included, and it never has to happen again.
Step 4: Point Your Workers at It
At this stage, you can connect your accelerators and start the billing process for them. Until now, you don't need to wait for them to be there, so in this example we created the Node Pools for GPU at Step 4.
Once you are done with GPUs, in your inference deployment, mount the same PVC and set the same HF_HOME:
env:
- name: HF_HOME
value: /cache/huggingface
volumeMounts:
- name: model-cache
mountPath: /cache/huggingface
readOnly: true
volumes:
- name: model-cache
persistentVolumeClaim:
claimName: model-cacheMark the mount readOnly in workers. Only the download Job should ever write. When a worker starts, the Hugging Face client checks the cache, finds the pinned revision already present, and goes straight to loading weights into GPU memory. Scale to 8 replicas and all 8 skip the download. Restart a pod at 3 a.m. and it is serving again in minutes.
Step 5: A Complete vLLM Example
Now let's try a complete example. Here is what the pattern looks like end to end with vLLM serving the cached model:
apiVersion: apps/v1
kind: Deployment
metadata:
name: qwen3-32b-vllm
spec:
replicas: 1
selector:
matchLabels:
app: qwen3-32b-vllm
template:
metadata:
labels:
app: qwen3-32b-vllm
spec:
containers:
- name: vllm
image: vllm/vllm-openai:latest
args:
- --model
- Qwen/Qwen3-32B
- --revision
- 9216db5781bf21249d130ec9da846c4624c16137
- --tensor-parallel-size
- "2"
env:
- name: HF_HOME
value: /cache/huggingface
ports:
- containerPort: 8000
resources:
limits:
nvidia.com/gpu: "2"
volumeMounts:
- name: model-cache
mountPath: /cache/huggingface
readOnly: true
volumes:
- name: model-cache
persistentVolumeClaim:
claimName: model-cacheThree details make this work. HF_HOME matches the download Job exactly, so vLLM's loader resolves Qwen/Qwen3-32B straight from the mounted cache. The --revision flag pins the same commit SHA the Job downloaded, so vLLM finds that exact snapshot on disk instead of reaching out to the Hub for a newer one. And no HF_TOKEN is needed at serve time, because the weights are already local.
The shape matches our node: one pod with --tensor-parallel-size 2 claims both A100 80GB GPUs, splitting the 65 GB of weights to roughly 33 GB per card and leaving generous room for KV cache. One replica is a hardware limit, not a storage one; add GPU nodes and the RWX cache lets you raise the replica count without any other change.
Apply it after the download Job completes and check the pods:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
model-download-5xqm4 0/1 Completed 0 15m
qwen3-32b-vllm-5bd8bbf484-7hpz6 1/1 Running 0 2m44sThe download Job sits Completed, its work done, and the vLLM pod is Running in under three minutes. Be aware of what Running means here: the container is up, but the model is not serving yet. The shards are still streaming from the shared volume into GPU memory, and that takes a few more minutes. The expensive part is already behind you, though; instead of a wall of download progress bars, the logs jump straight to loading from local disk:
(Worker_TP0) Filesystem type for checkpoints: NFS. Checkpoint size: 61.02 GiB. Available RAM: 325.58 GiB.
(Worker_TP0) Prefetching checkpoint files into page cache started (in background, num_threads=8)
Loading safetensors checkpoint shards: 47% Completed | 8/17 [05:49<02:00, 13.42s/it]
Loading safetensors checkpoint shards: 100% Completed | 17/17 [05:58<00:00, 21.06s/it]
(Worker_TP0) Model loading took 30.59 GiB and 360.698330 seconds
(Worker_TP1) Model loading took 30.59 GiB and 361.681247 secondsThe first line is the receipt: vLLM detected the checkpoint on NFS, our Filestore volume, and prefetched it through the page cache instead of touching the Hub. Six minutes later each worker holds its 30.59 GiB half of the tensor-parallel split.
You will also see a few Read-only file system warnings about a .no_exist path; that is vLLM trying to write a small cache marker into a volume we deliberately mounted readOnly, and it ignores the failure and continues. Harmless, and proof the mount is doing its job.
Step 6: Prove It Serves
The final check is a real request. Port-forward to the pod and hit the OpenAI-compatible API:
kubectl port-forward pod/qwen3-32b-vllm-5bd8bbf484-7hpz6 8000:8000curl -s http://localhost:8000/v1/models{"object":"list","data":[{"id":"Qwen/Qwen3-32B","object":"model",
"owned_by":"vllm","max_model_len":40960, ...}]}The model is registered. Now make it talk:
curl -s http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen3-32B",
"messages": [{"role": "user", "content": "Say hi in 5 words."}],
"max_tokens": 30,
"chat_template_kwargs": {"enable_thinking": false}
}'{"id":"chatcmpl-9ee52208cdfbe9fe","object":"chat.completion",
"model":"Qwen/Qwen3-32B",
"choices":[{"message":{"role":"assistant","content":"Hello, how are you?"},
"finish_reason":"stop"}],
"usage":{"prompt_tokens":19,"completion_tokens":7,"total_tokens":26}}Qwen3-32B, served across two A100s, answering from weights that were downloaded exactly once. Every restart, rollout, and scale-up from here on starts at the six-minute load-from-disk mark instead of the fifteen-minute download-plus-load mark, and the gap widens with every additional replica.
Bonus for Pipelines
If you want to chain things in CI or a GitOps pipeline, this is the step that guarantees ordering. Increase the timeout for very large models; 600 seconds is fine for a 32B model on decent bandwidth, but a 600 GB DeepSeek checkpoint needs hours, not minutes. This makes the cache an explicit gate in your deployment flow: nothing GPU-shaped starts until the download has proven it has finished:
kubectl wait --for=condition=Complete job/model-download --timeout=3600s \
&& kubectl apply -f vllm-deploy.yamlFinal Thoughts
Model caching is not clever. That is the point. It is a PVC, a Job, and a kubectl wait, and it removes the single largest source of dead GPU time in most inference deployments. The parameters that matter are few: RWX storage so every pod on every node shares one copy, a pinned revision so the cache is reproducible, a matching HF_HOME so pods actually find it, and enough memory on the Job for the transfer buffers you asked for.
Set it up once per model, and every deploy, scale-up, and restart after that starts from warm weights instead of a cold internet. Your GPUs should be generating tokens, not downloading them.
Share this post
Related Reading
How to Set Up a GPU-Enabled Kubernetes Cluster on GKE: Step-by-Step Guide for AI & ML Workloads
A step-by-step guide to setting up a GPU-enabled Kubernetes cluster on Google Kubernetes Engine for AI and ML workloads, with vCluster for improved GPU resource sharing across teams.
Everyone Wants Sovereign. Almost Nobody Agrees on What That Means
Sovereign cloud is the most overloaded term in 2026 procurement. Four distinct claims hide under that one word, and the gap between them is where audits go sideways.
Scaling Without Limits: The What, Why, and How of Cloud Bursting
How vCluster VPN enables seamless multi-cloud Kubernetes networking, allowing organizations to scale elastically across environments during demand spikes.
Enjoyed this post? Stay updated with new articles.
Subscribe via RSSThanks for reading.